
Indri: Ultralight Audio Model
Overview
Indri is a novel, ultra-small transformer-based TTS/ASR model that treats audio as discrete tokens. It supports both Hindi and English, and delivers high-quality, style-consistent speech synthesis and recognition—all in a 124 M-parameter footprint.
- HF : https://huggingface.co/11mlabs/indri-0.1-124m-tts
- Blog : https://www.indrivoice.ai/blog
Key Features
- Tiny & Fast: Just 124 M parameters (GPT-2 small backbone) yet achieves realtime on CPU and up to 10× realtime on consumer GPUs (e.g. RTX6000 Ada: 400 tokens/s, <20 ms to first token).
- Streaming & Voice-Cloning: Autoregressive audio-token decoding with streaming output; supports speaker style prompts (<5 s) for consistent voice cloning.
- Bilingual & Code-Mixing: Natively handles English, Hindi, and mixed-language inputs.
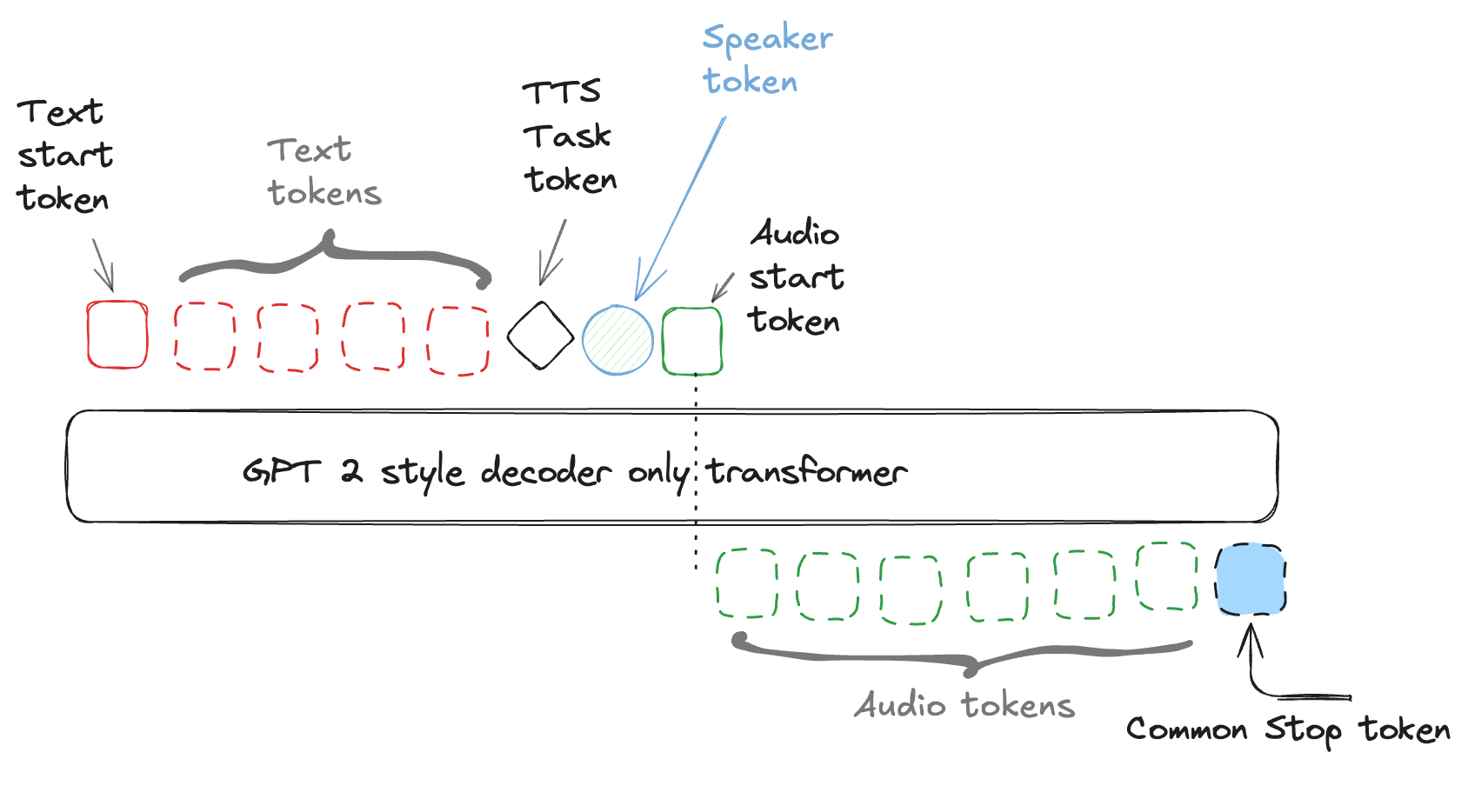
- End-to-End Pipeline:
- Text → text-tokens
- GPT-2 LM → audio-tokens
- Mimi decoder → waveform
- Novel architecture combining transformers with audio tokens, bringing text and audio to same space.
Audio Samples
- Sample 1: मित्रों, हम आज एक नया छोटा और शक्तिशाली मॉडल…
- Sample 2: भाइयों और बहनों, ये हमारा सौभाग्य है कि…
- Sample 3: Hello दोस्तों, future of speech technology mein…
- Sample 4: In this model zoo, a new model called Indri…
Links & Resources
- Blog post: Building Indri TTS
- Model & demos: 11mlabs/indri-0.1-124m-tts on Hugging Face
- Code & self-hosted service: github.com/indri-voice/indri