
MM-Duplex
This is an incomplete experiment. It trains a vlm with single token per image and the resulting vlm is very good for describing simple videos.
Humans can handle both input and output streams together. Like a commentator reciting the events of a match can both see and talk together. LLMs of today can either consume or produce tokens at a time making such tasks impossible in real time. In this paper we present MM-Duplex, a multimodal duplex architecture that takes video stream as a input and produces a text/audio stream as output.
Video -> text/audio “duplex”
- No existing model truly interleaves live video input with simultaneous commentary output.
- Current streaming video captioners buffer or segment frames before decoding, so they remain one-way pipelines rather than full-duplex.
Problems in current VLMs
- Too many image tokens: Image tokenizers emit 64 tokens per image. At 5fps this is 320 tokens/sec or 64x5x60 = 19200 tokens/min. A commentator would speak about 600 tokens in same time. Thus the discrepancy between video and text tokens is very high. Audio tokenizers such as Mimi use ~12.5 semantic tokens/second. Since not many things are changing in a video every second, most image tokens contain redudant information. We need a new video tokenizer that creates tokens with only new information. We propose a new architecture to tokenize videos motivated from B-frames which attends to changes and emits 64 tokens/second. ## TODOS
VLM
- train a clip like model from scratch
- train a vlm with existing clip head
streaming vid model
- moshi like model but with existing clip and llm
- see where best returns are, in tokenizer or out of it
- One modality at a time architecture: VLMs model image and text together by first mapping images to text space and then modelling them together as a language. This works very well for documents where there is only one modality present at one temporal and spatial position. But in real world interactions, multiple modalities are present together at same instance of time. This makes it impossible for VLMs to model interactions.
- Input/output half-duplex: Since VLMs model both input and output as a part of single sequence, only one of them can be present at a time instance. Although alternatives like alternate token weaving have been attempted before, large difference in token frequencies of different modalities make stable training of such networks unfeasible. In Moshi, kyutai proposes an alternative architecture for interactions that models both input and output as separate streams.
Proposed architecture
-
B-Flow Video tokenizer: Split video information into b-frames and flow. If flow is high use more b-frames. B-frames get fully tokenized. Flow tokens get tokenized depending on flow rate. Test on video captioning. This is a highly efficient streaming video tokenizer.
-
MM-Duplex: Delayed but aligned streams like moshi. This is a duplex video understanding model.
Resource estimates
Video tokenizer
- Clip takes 800xH100 hours to train with 400M images : 1600$
- Retrain a new type of tokenizer which encodes flows and events not images. Small model 75M, should be enough to understand basic things in videos.
- H100 for 10 days in a month = 55k Rs.
- All small experiments on 4090. Freeeee. Use hyperbolic for 5090s.
- timed transcriptions are video equivalent of captions for images. Can we train a model that aligns video with event transcriptions ?
MM-Duplex
- Moshi like structure with small text model (300M). Here videos are preencoded and we need to just train a projector. Projection layer of 100M ?
- Video encoding and text decoding work in parallel. What is the arch for keeping so much video information in context ? Are we going to compress video info using a tokenizer that encodes events, or are we going to make something that compresses the result of tokenizer more efficiently.
Past
Many attempts have been made on audio-audio duplex streaming as follows.
-
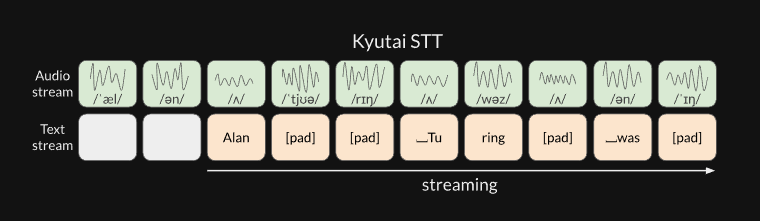
Moshi: a speech-text foundation model for real-time dialogue A full-duplex speech-to-speech foundation model that replaces traditional VAD→ASR→NLU→NLG→TTS pipelines with a single streaming Transformer.
Moshi introduces tokenizer mimi that compresses audio to 12.5 tokens per second per codebook with 8 codebooks giving close to real audio.
They also build an architecture to weave a text and audio streams together, which they call delayed-streams-modeling. They build other models like an stt, tts and a streaming speech-speech translator using same arch.
TODOS
VLM
- train a clip like model from scratch
- train a vlm with existing clip head
streaming vid model
- moshi like model but with existing clip and llm
- see where best returns are, in tokenizer or out of it
Think, training video tokenizer from scratch is going to be very hard. Instead figuring out an arch that can
- stream
- express videos as events without training clip like thing from scratch
Measurement
- LongVideoBench https://longvideobench.github.io/
- ReasoningVideo lyx97/reasoning_videos
- Natural video commentary arena [None yet. Look equivalent for audio]
Training dataset
- PEVideo : https://huggingface.co/datasets/facebook/PE-Video : 1M videos, 500M frames@30fps. PLM was trained on 90M images.
- Live CC dataset: 5M videos